Discovering Site Reliability Engineering December 2020 Telia SRE Webinar Bruno Amaro Almeida @bruno_amaro Photo by Chris Liverani on Unsplash
Slide 1

Slide 2

● What is Site Reliability Engineering? INDEX ● Benefits & Results of Adopting an SRE Mindset ● Developing a SRE Culture ○ SRE vs DevOps ○ SRE <> 24/7 operations ○ Understanding SLO’s ● SRE & Technology Governance in Enterprise Scale BERLIN · HELSINKI · LONDON · MUNICH · OSLO · STOCKHOLM · STUTTGART · TAMPERE
Slide 3

Thank you! Kiitos! Danke! Tack! Hello! Bruno Amaro Almeida HEAD OF ARCHITECTURE & ADVISOR Cloud, DevOps, Security, Data Engineering & AI Reach out on: @bruno_amaro @brunoamaroalmeida BERLIN · HELSINKI · LONDON · MUNICH · OSLO · STOCKHOLM · TAMPERE
Slide 4

ABOUT FUTURICE Nordic roots, global mindset 600+ People 38 19 Years in Business Nationalities TRE HEL 8 Offices 30% OSL 3000+ YOY Growth STHL M Projects Our family of companies LDN eCommerce and Artificial Intelligence and Machine Growth-Hacking Learning BER Platform for freelance tech professionals STGT MUC Map background designed by @Freepik
Slide 5

What is SRE? What is Site Reliability Engineering (SRE)? Google has spent years running systems in massive scale. Over time, we’ve standardize our practices to balance our velocity of features with the risk to reliability, both for us and for our customers. Those practices, combined with a culture to support them, we call Site Reliability Engineering or SRE. Source: Developing an SRE Culture, Google Photo by John Moeses Bauan on Unsplash
Slide 6

What is SRE? Key Elements of the SRE Model Site Reliability Engineering (SRE) What is it, what are the advantages, and how do I implement it?
Slide 7

Developing a SRE Culture SRE vs DevOps “DevOps is the combination of cultural philosophies, practices, and tools that increases an organization’s ability to deliver applications and services at high velocity(…)” source: amazon.com SRE is a practical way to implement DevOps SRE practices align to DevOps pillars philosophy Developers focus on feature velocity and innovation; operators focus on reliability and consistency. source: Google Source: Developing an SRE Culture, Google
Slide 8

Benefits & Results Benefits & Results of Adopting an SRE Mindset “A History of Site Reliability Engineering at Uber” by Rick Boone
Slide 9

Benefits & Results Benefits & Results of Adopting an SRE Mindset SRE incorporates aspects of software engineering and applies them to IT operations ● Helps software systems to evolve and continuously improve on availability, latency, performance and capacity. ● Enables the organization to create a common language among Engineering teams ● SRE culture brings a unified vision, promoting collaboration and knowledge sharing within teams. ● Operations is treated a value center, not cost center. Source: devoptopologies.com
Slide 10

Developing a SRE Culture Understanding SLO’s & SLI’s • Blameless postmortem: Detailed documentation of an incident or outage, its root cause, its impact, actions taken to resolve it, and follow-up actions to prevent its recurrence. • Reliability: The number of “good” interactions divided by the number of total interactions. This leaves you with a numerical fraction of real users who experience a service that is available and working. • Error budget: The amount of unreliability you are willing to tolerate. • Service level indicator (SLI): A quantifiable measure of the reliability of your service from your users’ perspective. • Service level objective (SLO): Sets the target for an SLI over a period of time. Source: Developing an SRE Culture, Google Photo by Elisa Michelet on Unsplash
Slide 11

Developing a SRE Culture API Service Reliability: worked well S times out of a total of T times. R = S/T Error Budget: How much unreliability (100% - R) is ok? Service Level Indicator (SLI): HTTP 2xx, HTTP 5xx, End to End Latency Service Level Objective (SLO): • 99% HTTP 2xx monthly • max. 1% HTTP 5xx monthly • Latency of every request is below 200ms monthly ❗100% reliability is a wrong target because it will impact the release speed of new features
Slide 12

“ Everything Fails All the Time Werner Vogels - CTO, Amazon Web Services
Slide 13

Developing a SRE Culture Make Tomorrow Better than Today ● ● ● ● ● ● ● Change is best when small and frequent. Design thinking methodology has five phases: empathize, define, ideate, prototype, and test. Prototyping culture encourages teams to try more ideas, leading to an increase in faster failures and more successes. Excessive toil is toxic to the SRE role. By eliminating toil, SREs can focus the majority of their time on work that will either reduce future toil or add service features. Resistance to change is usually a fear of loss. Present change as an opportunity, not a threat. People react to change in many ways, and IT leaders need to understand how to communicate with and support each group. Source: Developing an SRE Culture, Google Photo by Pablo Heimplatz on Unsplash
Slide 14

Developing a SRE Culture Getting Comfortable with Failure Blameless Postmortem: For every failure a detailed incident RCA, with impact assessment and concrete actions to prevent its recurrence. Fostering Psychological Safety is key to learn and innovative in organizations. Part I: What happened? Impact, RCA, Lessons Learn, Where did we get lucky? Part II: What can we do differently next time? Actions, Owners, Prioritization
Slide 15

Developing a SRE Culture SRE <> 24/7 operations ❓How much unreliability are you willing to tolerate? How often do you want to release new features? Principal Engineer at AWS ex-Google SRE The SRE Model
Slide 16

Developing a SRE Culture SRE <> 24/7 operations ❓How much unreliability are you willing to tolerate? How often do you want to release new features? SLOs and Error Budgets create a contract (shared responsibility and ownership) between developers, SREs and business. An SRE team often provides a checklist (e.g. load test, tolerant to region failures, runbook/playbook) of requirements to go live and support 24/7 operations. ⚠On-call rotation should have enough people to avoid burnout. Geo-distributed teams/people help a lot. System-level SLOs System-level SLOs Tenant-level SLOs Tenant-level SLOs Organization-level SLOs 100% of help calls will be answered within 20 minutes System-level SLOs
Slide 17

Technology Governance What is an SRE Team? Platform / SysOps/ SRE Platform / SysOps / SRE team provides support and enablement: • • • • • Baseline infrastructure & toolset Production Readiness Checklist Documentation and Guidelines Security Threat Modelling 24/7 Support What you should consider and not How you need to do it. Source: Developing an SRE Culture, Google BERLIN · HELSINKI · LONDON · MUNICH · OSLO · STOCKHOLM · TAMPERE
Slide 18
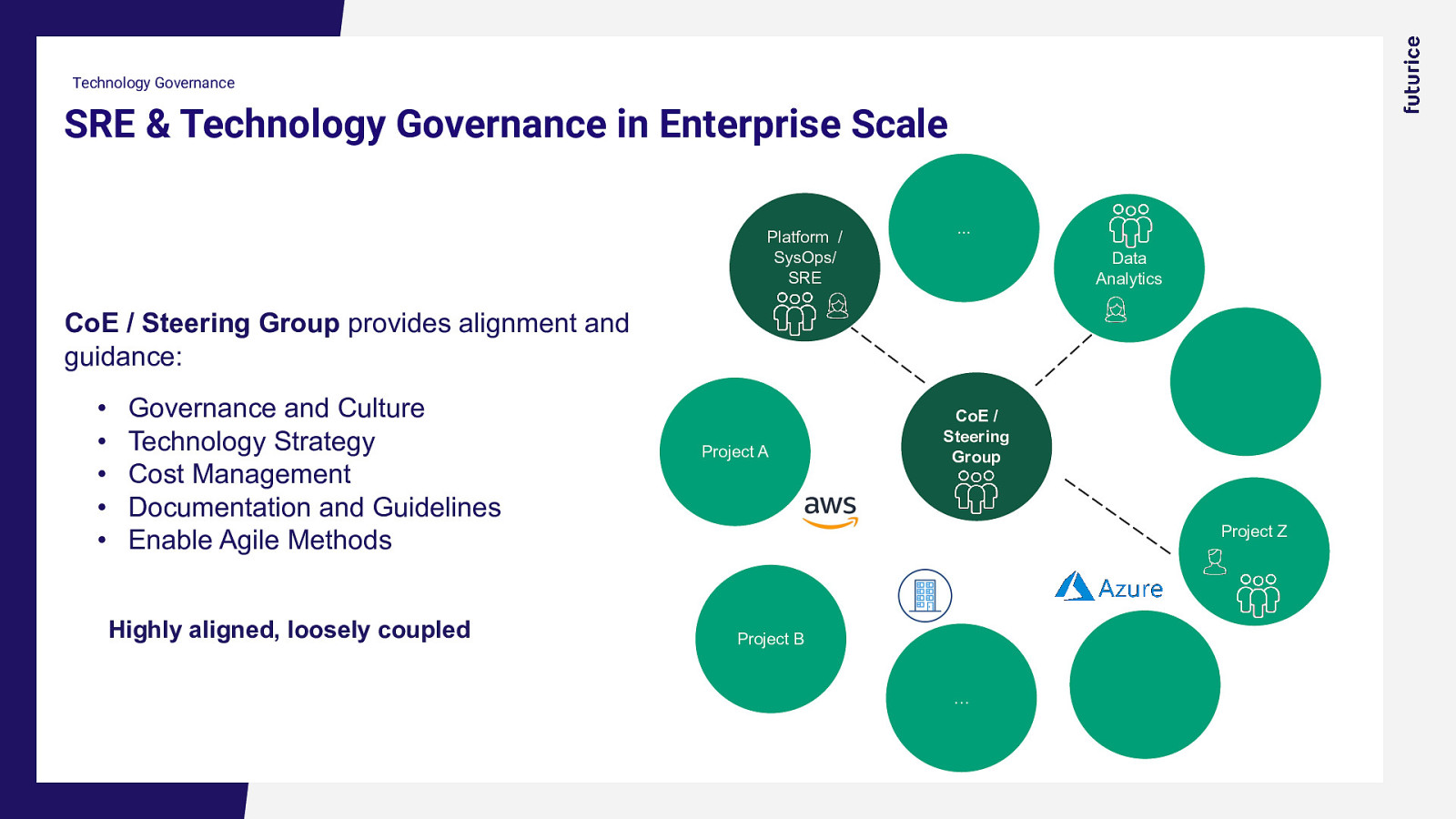
Technology Governance SRE & Technology Governance in Enterprise Scale Platform / SysOps/ SRE … Data Analytics CoE / Steering Group provides alignment and guidance: • • • • • Governance and Culture Technology Strategy Cost Management Documentation and Guidelines Enable Agile Methods Highly aligned, loosely coupled Project A CoE / Steering Group Project Z Project B …
Slide 19
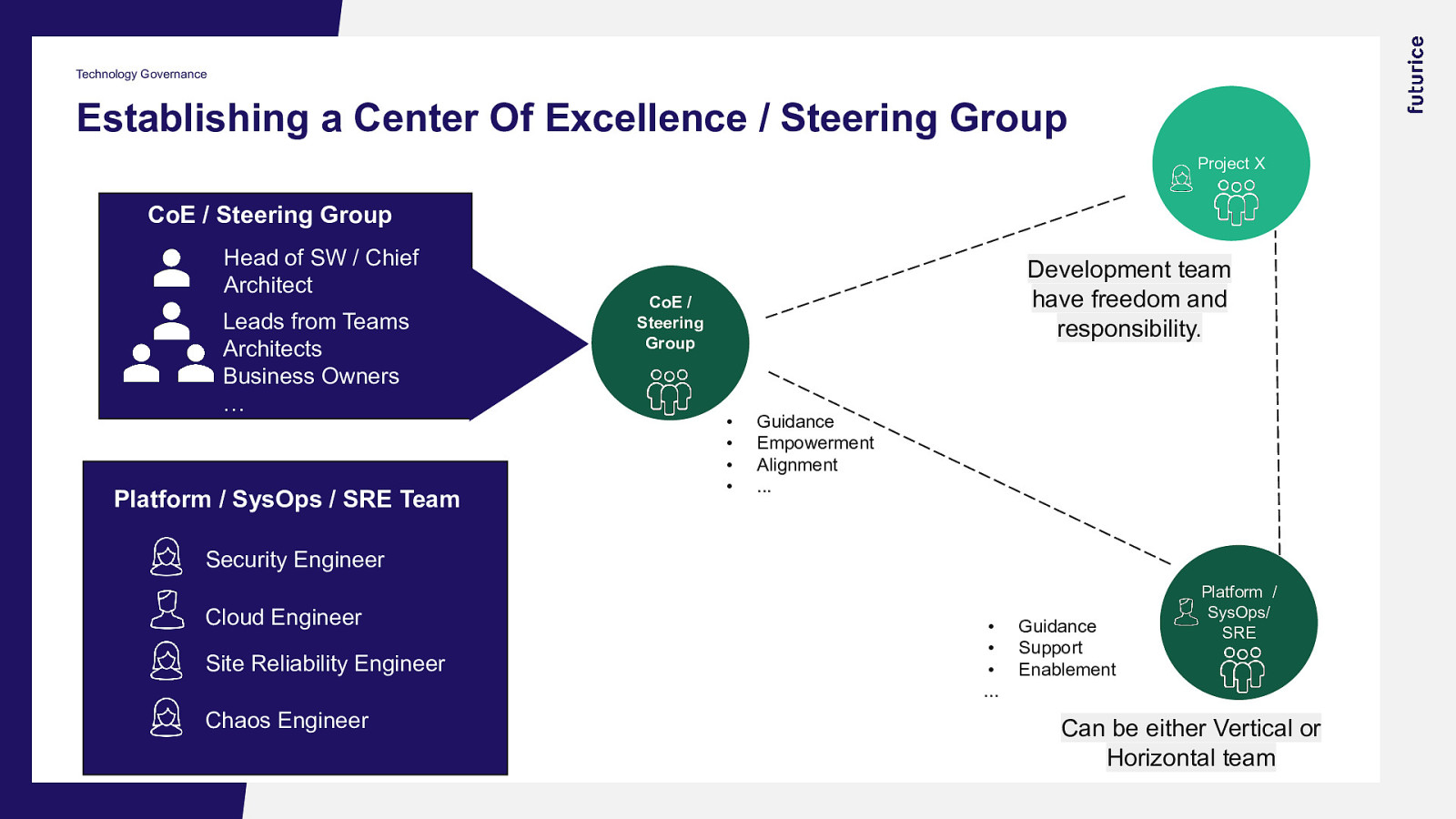
Technology Governance Establishing a Center Of Excellence / Steering Group Project X CoE / Steering Group Head of SW / Chief Architect Leads from Teams Architects Business Owners … Platform / SysOps / SRE Team Development team have freedom and responsibility. CoE / Steering Group • • • • Guidance Empowerment Alignment … Security Engineer Cloud Engineer Site Reliability Engineer Chaos Engineer • • • … Guidance Support Enablement Platform / SysOps/ SRE Can be either Vertical or Horizontal team
Slide 20
Learn more about SRE Discovering SRE
Slide 21

Thank you! Kiitos! Danke! Tack! Bruno Amaro Almeida HEAD OF ARCHITECTURE & ADVISOR Cloud, DevOps, Security, Data Engineering & AI Reach out on: @bruno_amaro @brunoamaroalmeida BERLIN · HELSINKI · LONDON · MUNICH · OSLO · STOCKHOLM · TAMPERE