The Hitchhiker’s Guide to AI & ML Index In AWS (workshop) AWS Community Day Nordics Stockholm 2020 Bruno Amaro Almeida BERLIN · HELSIN K I · LON DON @bruno_amaro · MUN ICH · OSLO · STOCK HOLM · TAMPERE Photo by Atlas Green on Unsplash
Slide 1

Slide 2

ABOUT FUTURICE Nordic roots, global mindset 38 600+ 19 People 8 Offices Years in Business Nationalities 30% TRE 3000+ YOY Growth HEL OSL STHLM Projects Our family of companies LDN eCom m erce and Grow thHacking Artificial Intelligence and M achine Learning BER Platform for freelance tech professionals STGT MUC Map background designed by @Freepik
Slide 3

OUR OFFERING We co-create resilient future for you Data and Cloud Platforms Transformative Experiences Innovative and Data-driven Organisations Software Development Intelligent Services and Ecosystems Transform your business in the cloud A game-changing experience will set you apart Future-capable organisations learn fast and live long The modern enterprise relies on fast, high-quality software delivery Make complexity your competitive edge Learn more about our offering in http://futurice.com/services
Slide 4

// Agenda 1. Introductions (15 minutes) 2. 30.000ft view (10 minutes) 3. Data Ingestion (5 minutes 4. Data Preparation (15 minutes) 5. Algorithms & Validation (1h 30 minutes) • • Hands-on AWS SageMaker Hands-on AWS Cognitive Services 6. Next Steps, Feedback and Q&A (15 minutes) BERLIN · HELSIN K I · LON DON · MUN ICH · OSLO · STOCK HOLM · TAMPERE @bruno_amaro
Slide 5

Thank you! Kiitos! Danke! Tack! Hello! Bruno Amaro Almeida P RINC IP AL ARC HITE C T & ADV ISOR Cloud, DevOps, Security, Data Engineering & AI Reach out on: @bruno_amaro @brunoamaroalmeida BERLIN · HELSIN K I · LON DON · MUN ICH · OSLO · STOCK HOLM · TAMPERE
Slide 6

- // 30.000ft view • • • • • Goals & Prerequisites What is AI, ML & Data Science? Data Engineering vs Data Science AI/ML Cycle, a 15.000 view Data Science AWS services @bruno_amaro
Slide 7

S Y S T E M S C H E C K Workshop Goals & Prerequisites A • Core Data Science concepts • AI and Machine Learning landscape in AWS • To leverage the pre-trained AI/ML model API’s in AWS • To build, train and deploy a ML model What do you need for the workshop? • Prerequisites for the hands-on (required) An AWS account with a user with full rights (admin) • (preferred) Python 3 installed on your laptop • • (preferred) AWS CLI installed on your laptop (optional) a GitHub account What will you learn? Goals for this workshop B Kick start your Data Science knowledge using AWS services @bruno_amaro
Slide 8

W HAT IS W HAT? What is AI, ML, Data Science etc? Artificial intelligence (AI): computer systems that accomplishes goals in some task(s). It is not a single Artificial Intelligence thing; it is a combination of technologies such as machine learning. Machine Learning Machine Learning (ML): toolbox of algorithms and techniques that learn rules from data. Used to implement AI in narrow tasks. Not magic; learns from Deep Learning the data by minimising a cost function. Deep Learning one of the most popular tools from the Machine Learning toolbox. Particularly effective when the dataset is very large. @bruno_amaro
Slide 9
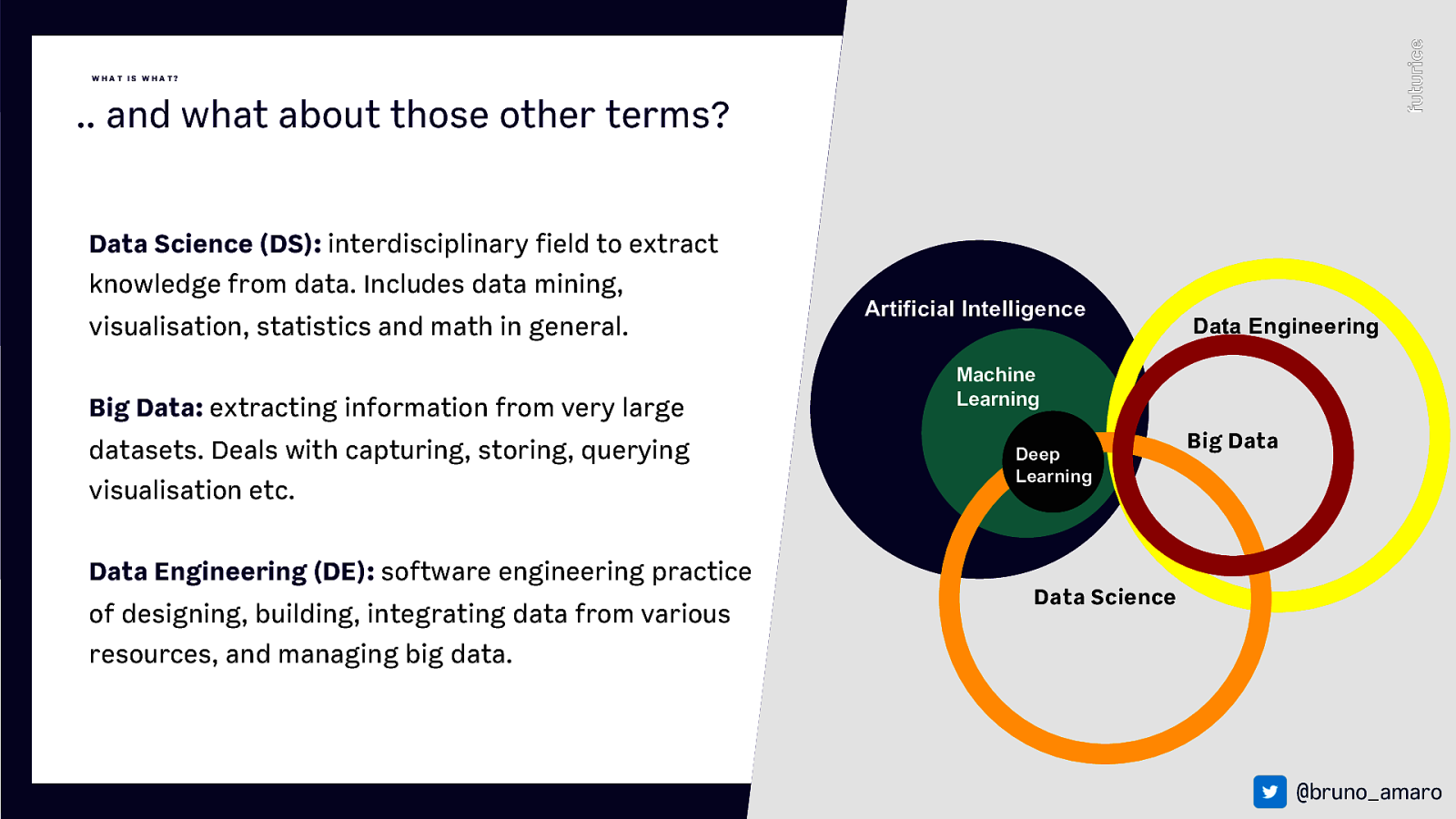
W HAT IS W HAT? .. and what about those other terms? Data Science (DS): interdisciplinary field to extract knowledge from data. Includes data mining, visualisation, statistics and math in general. Big Data: extracting information from very large datasets. Deals with capturing, storing, querying visualisation etc. Artificial Intelligence Data Engineering Machine Learning Deep Learning Big Data Data Engineering (DE): software engineering practice of designing, building, integrating data from various Data Science resources, and managing big data. @bruno_amaro
Slide 10
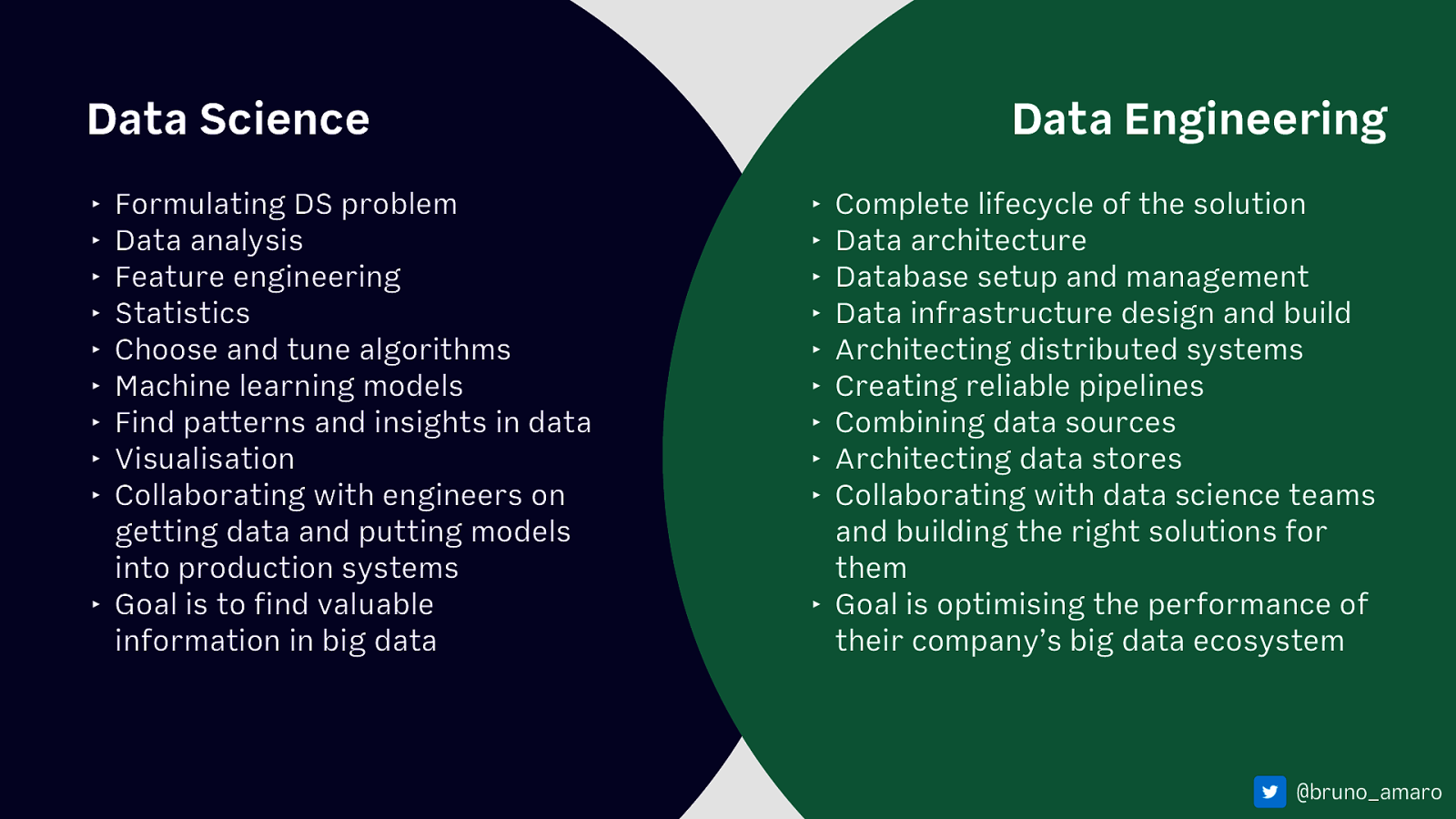
Data Science ‣ ‣ ‣ ‣ ‣ ‣ ‣ ‣ ‣ Formulating DS problem Data analysis Feature engineering Statistics Choose and tune algorithms Machine learning models Find patterns and insights in data Visualisation Collaborating with engineers on getting data and putting models into production systems ‣ Goal is to find valuable information in big data Data Engineering ‣ ‣ ‣ ‣ ‣ ‣ ‣ ‣ ‣ Complete lifecycle of the solution Data architecture Database setup and management Data infrastructure design and build Architecting distributed systems Creating reliable pipelines Combining data sources Architecting data stores Collaborating with data science teams and building the right solutions for them ‣ Goal is optimising the performance of their company’s big data ecosystem @bruno_amaro
Slide 11

AWS: Core Building Blocks Compute Network Storage Security & Identity • AWS EC2 • AWS VPC • AWS EBS • AWS IAM • AWS ECS / EKS / Fargate • AWS Route 53 • AWS S3 • AWS KMS / CloudHSM • AWS Lambda • AWS Elastic Load Balancing • AWS EFS • AWS Inspector / Advisor / GuardDuty / Shield • AWS Elastic Beanstalk / Amplify • AWS CloudFront Message Queues, Logging, Monitoring Databases • AWS SNS • AWS RDS • AWS CloudWatch • AWS DynamoDB • AWS SQS • AWS Neptune • AWS Kinesis • AWS ElasticCache • AWS RedShift @bruno_amaro
Slide 12
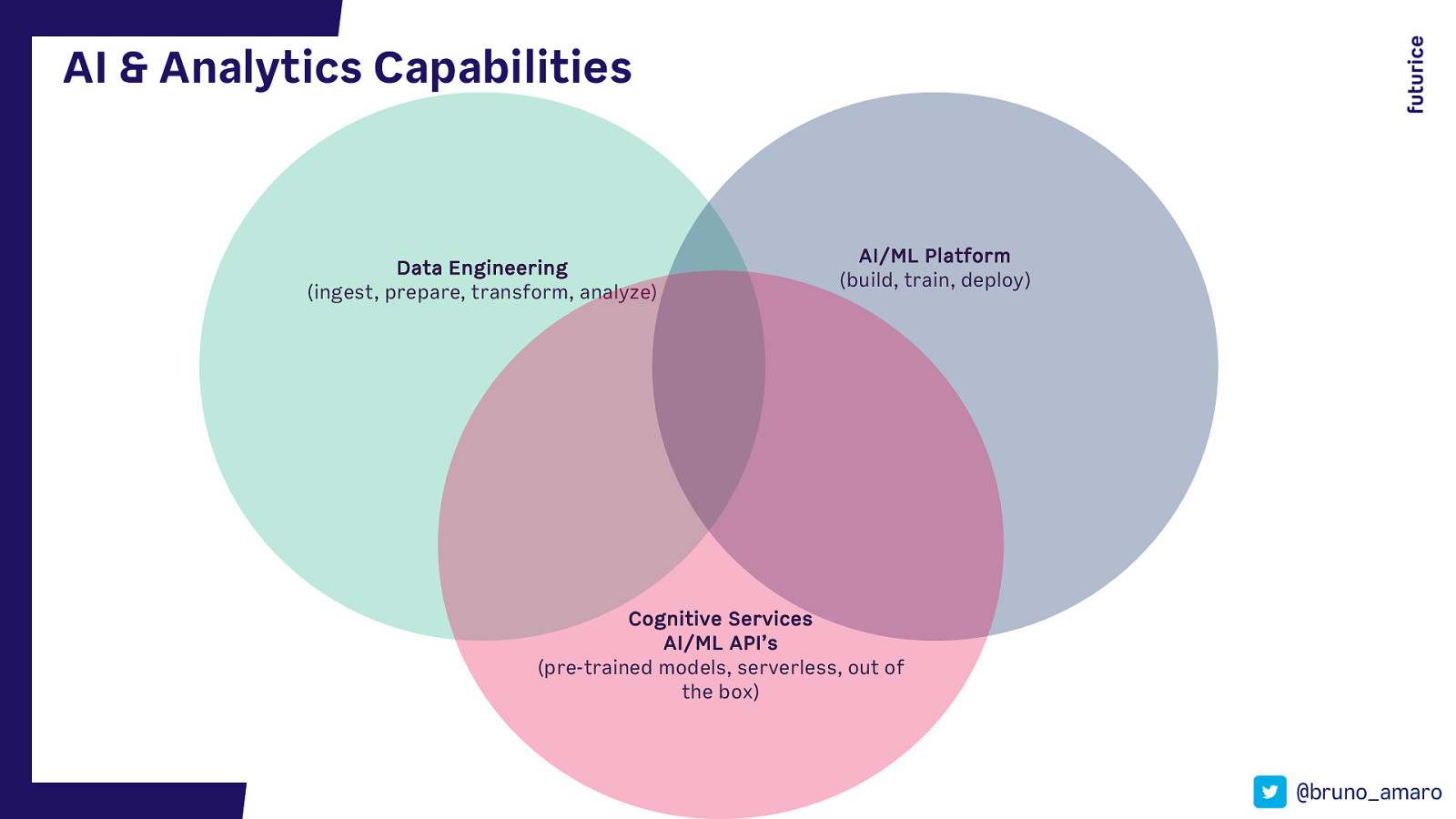
AI & Analytics Capabilities Data Engineering (ingest, prepare, transform, analyze) AI/ML Platform (build, train, deploy) Cognitive Services AI/ML API’s (pre-trained models, serverless, out of the box) @bruno_amaro
Slide 13
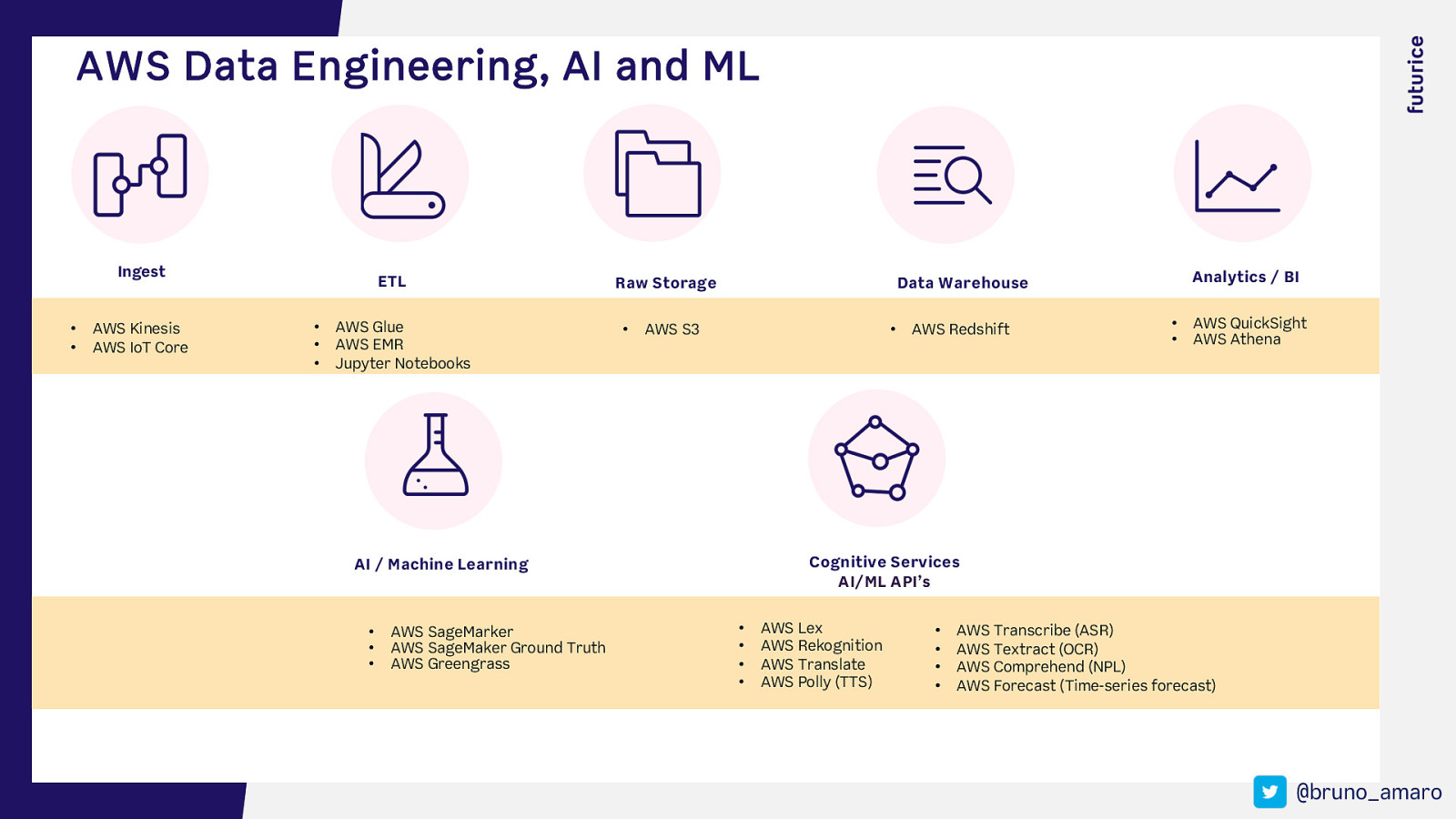
AWS Data Engineering, AI and ML Ingest • AWS Kinesis • AWS IoT Core ETL Raw Storage • AWS Glue • AWS EMR • Jupyter Notebooks • AWS S3 Data Warehouse • AWS Redshift • AWS QuickSight • AWS Athena Cognitive Services AI/ML API’s AI / Machine Learning • AWS SageMarker • AWS SageMaker Ground Truth • AWS Greengrass Analytics / BI • • • • AWS Lex AWS Rekognition AWS Translate AWS Polly (TTS) • • • • AWS Transcribe (ASR) AWS Textract (OCR) AWS Comprehend (NPL) AWS Forecast (Time-series forecast) @bruno_amaro
Slide 14
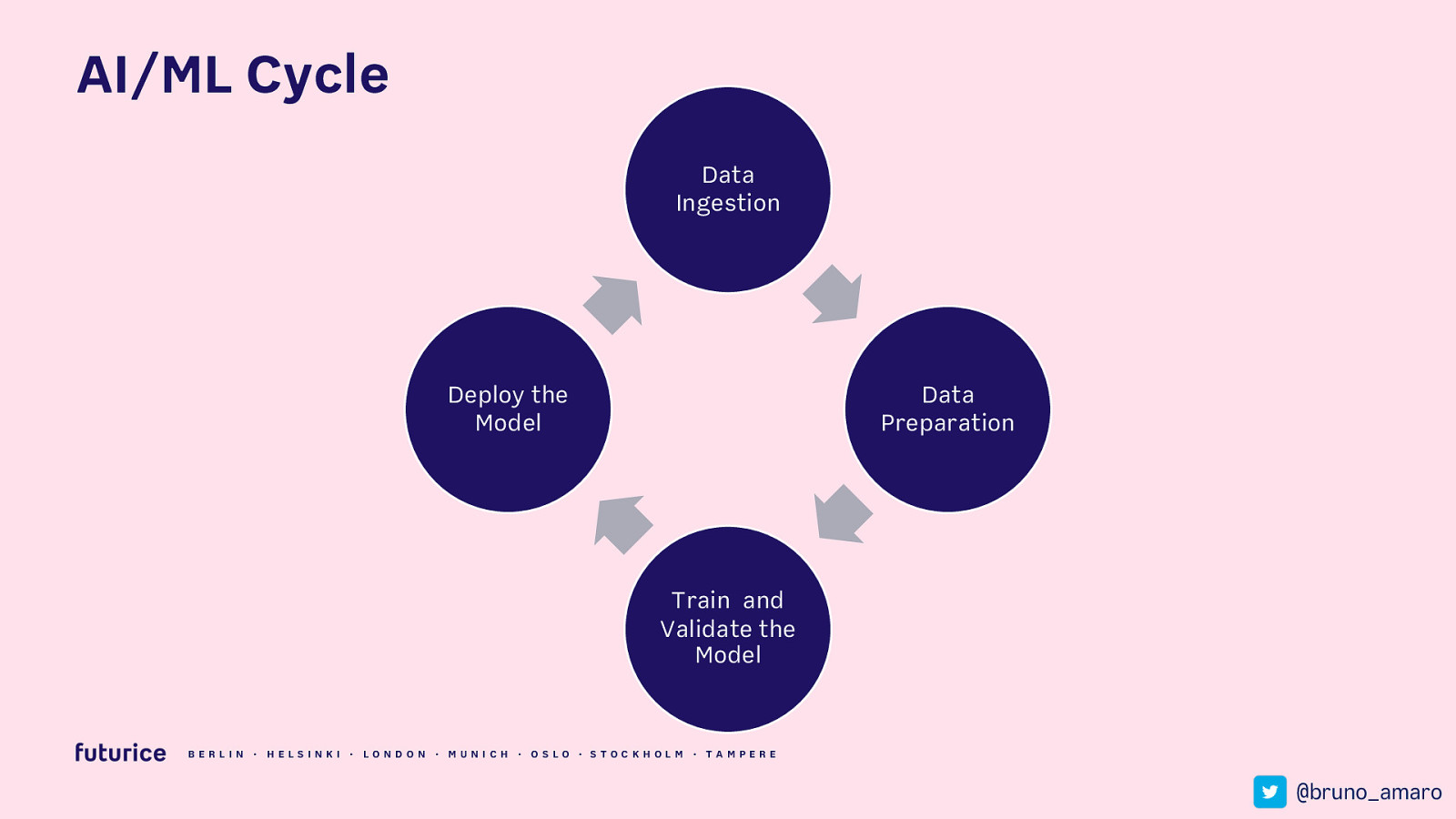
AI/ML Cycle Data Ingestion Deploy the Model Data Preparation Train and Validate the Model BERLIN · HELSIN K I · LON DON · MUN ICH · OSLO · STOCK HOLM · TAMPERE @bruno_amaro
Slide 15
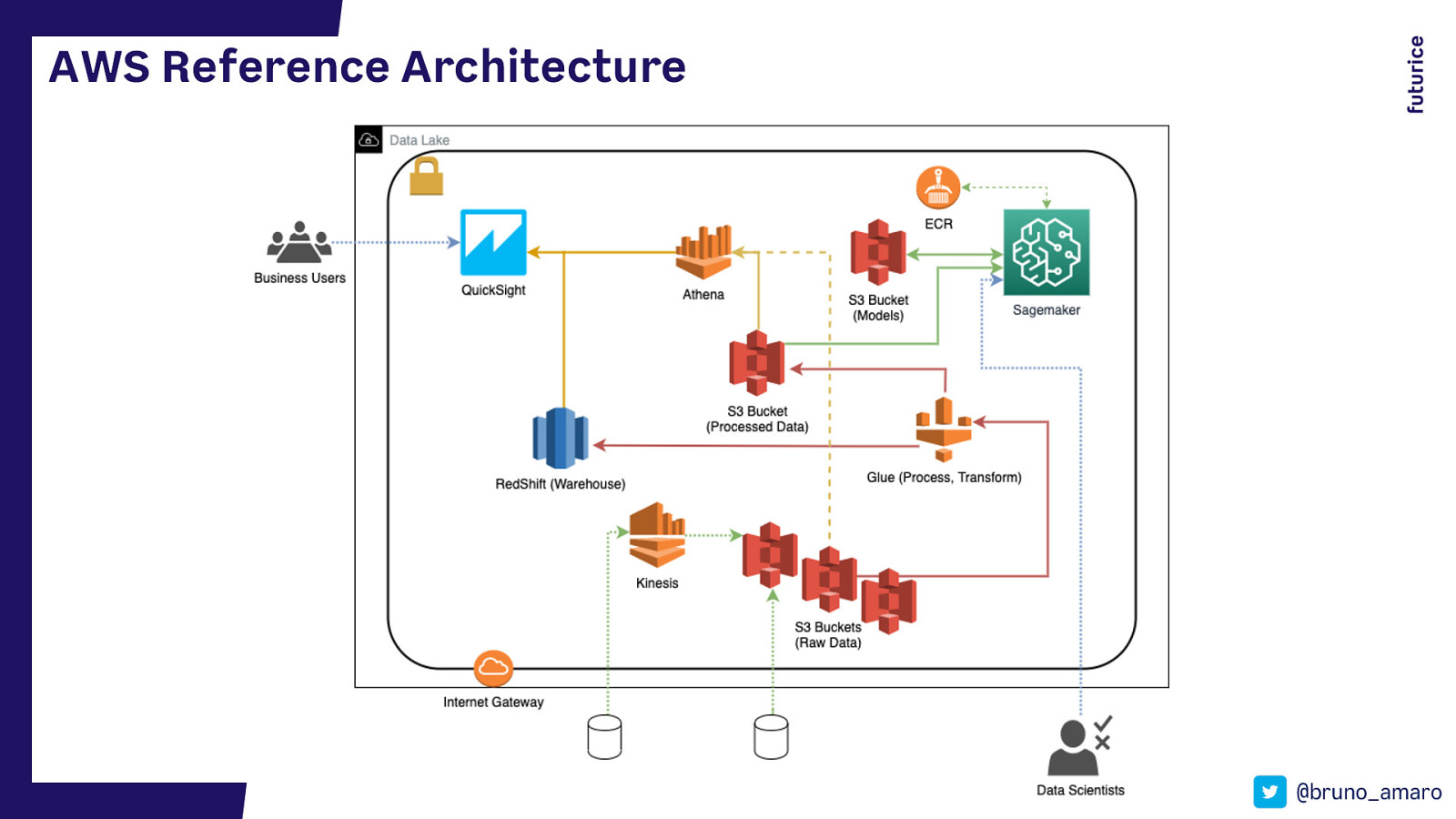
AWS Reference Architecture @bruno_amaro
Slide 16

- // Data Ingestion How can we acquire data? @bruno_amaro
Slide 17

Public Datasets Fantastic datasets and where to find them § AWS Public Dataset Program (Open Data Registry on AWS) § Kaggle § Finland Avoin Data § MNIST § …. Source: https://researchgate.net, http://yann.lecun.com/exdb/mnist/ Photo by Alexander Sinn on Unsplash @bruno_amaro
Slide 18

HOW CAN W E ACQUIRE DATA? Multiple ways to ingest data 1 One-Time Import In AWS using: You manually import a dataset. S3 2 Periodic Polling DMS In AWS using: Every x amount of time, you fetch data from a system or API Fargate Lambda 3 Request based In AWS using: A system or a user interact sends you data via an API. API GW Lambda 4 Near Real-time ELB Fargate In AWS using: You have one or more systems or devices streaming data to you. Kinesis IoT Core @bruno_amaro
Slide 19
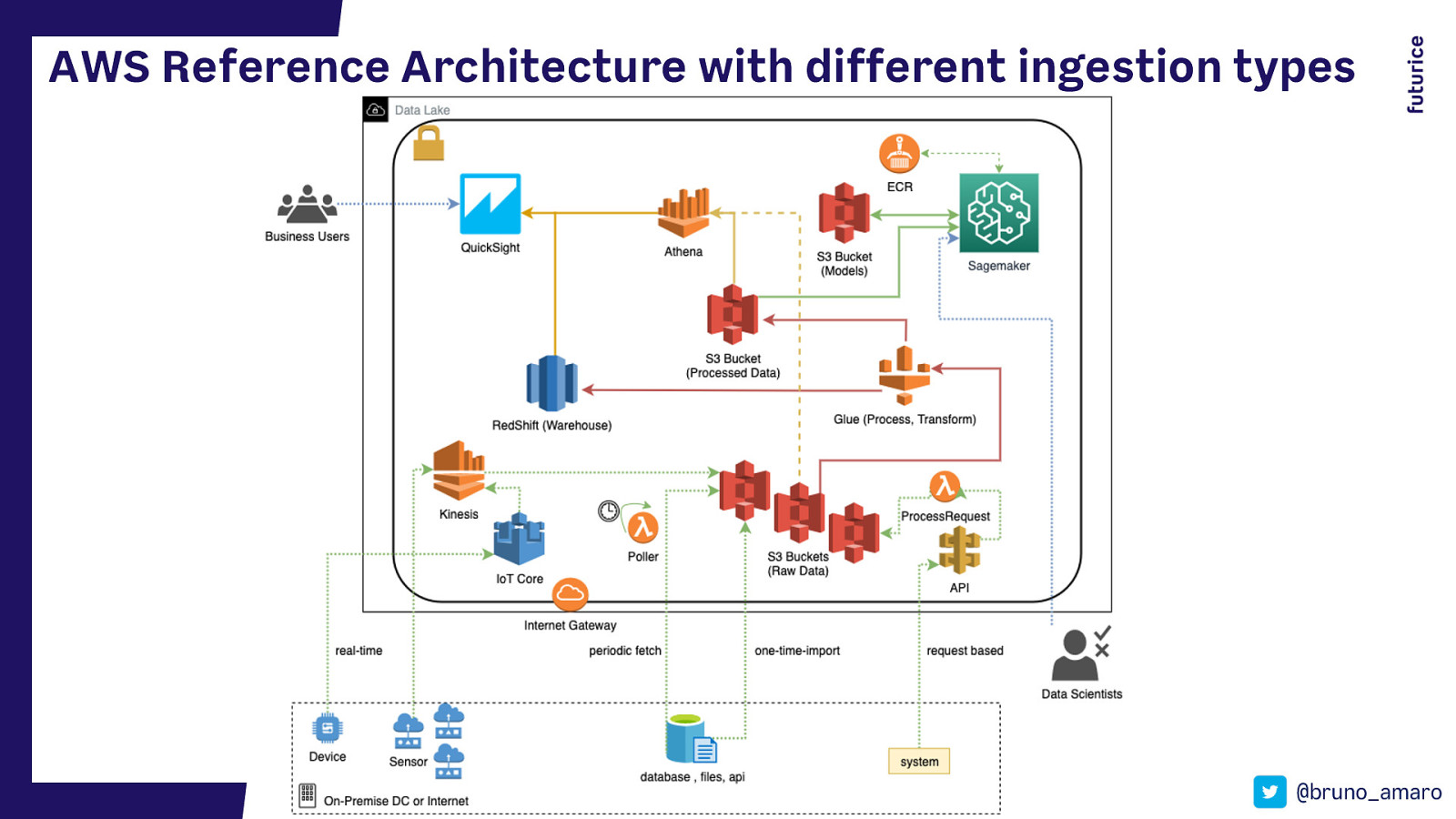
AWS Reference Architecture with different ingestion types @bruno_amaro
Slide 20

- // Data Preparation • • • • What is data preparation? How? Why is this important? Ways to transform data @bruno_amaro
Slide 21

D A T A P R E P A R A T I O N What, Why, How? Concepts A What is data preparation? Transforming our data to make it usable by Machine Learning and / or Analytics B Why is this important? • Over simplification: Algorithms <3 numbers • Algorithms need a lot of data and with good quality to be efficient. How? • Process: Extract, Transformation, Load (ETL) Extract: read the data into a usable format (json, csv, parquet, etc) • Transformation: clean & transform features so that the data can be usable by algorithms or analysis Load: write the new data into a place that can be usable (data warehouse, object storage, etc) Garbage in < Garbage out > C Ways to do Transformation: Categorical Encoding, Feature Engineering, … • @bruno_amaro
Slide 22

DATA PREPARATION Ways to transform data: Categorical A Encoding and Feature Engineering Categorical Encoding PhoneBrand Brand_Apple Brand_Samsung Apple 1 0 Samsung 0 1 One-hot encoding Text to Numbers: Nominal vs Ordinal B S M L Text Feature N-gram Term Frequency – Inverse Document Frequency (tf-id) Orthogonal Sparse Bigram (OSB) N-Gram http://recognize-speech.com/language-model/n-gram-model/comparison C Numeric Feature 0 1.0 avg Scaling (e.g. Normalization, Standardization) Binning (e.g. Quantile) z-score To deal with outliers! Groups of similar values D Missing data? Too many features? Missing data can be dealt in different ways: supervised learning, mean, median, drop values Feature selection: remove useless features! 0-17 18-64 65+ Principle Component Analysis (PCA) is an algorithm that reduces the amount of features @bruno_amaro
Slide 23

D A T A P R E P A R A T I O N AWS Services for ETL 1 AWS Glue Recommended AWS way to implement an ETL process > Python, Scala or Spark support > Features such as Crawlers, Catalog, Integration with other AWS services, Serverless 2 AWS EMR Elastic Map Reduce as a Service > Hadoop, Spark, etc. 3 Jupyter Notebooks (AWS Sagemaker) It’s possible to do ETL via Jupyter but only ad-hoc, non-automated cases (during research) > Python @bruno_amaro
Slide 24

- // Algorithms & Validation Building Intelligence on top of our data @bruno_amaro
Slide 25

ALGORITHMS Concepts > Algorithm (consistent) vs Heuristic (rule of thumb, no consistent outcome) > Supervised Learning (training, labels) vs Unsupervised Learning (no training or supervision) How can you use algorithms in AWS (Sagemaker)? You can use the algorithms built-in Sagemaker B E R L I N · T A M P E R E H E L S I N K I · L O N D O N You can build your own algorithm (& place it in a Docker container) You can purchase algorithms from Marketplace · M U N I C H · O S L O · S T O C K H O L M · S T U T T G A R T · @bruno_amaro
Slide 26

A L G O R I T H M S (some) Types of Algorithms A Clustering Unsupervised algorithms that aim to group features (e.g. K-means) B Classification Algorithms that aim to classify features (e.g. K-means, K-nearest) C Anomaly detection Algorithms that detect anomalies (e.g. Random Cut Forest) D Text Analysis Algorithms that analyze text (e.g. Latent Dirichlet Allocation (LDA), Neural topic model (NTM), Sequence to Sequence, Blazing Text ) E Reinforcement Learning Algorithms that find the path to the greatest reward (e.g. Markov Decision Process) > AWS DeepRacer! F Regression Algorithms that estimate the relation between dependent values (e.g. Linear Regression, Logistics Regression, …) @bruno_amaro
Slide 27
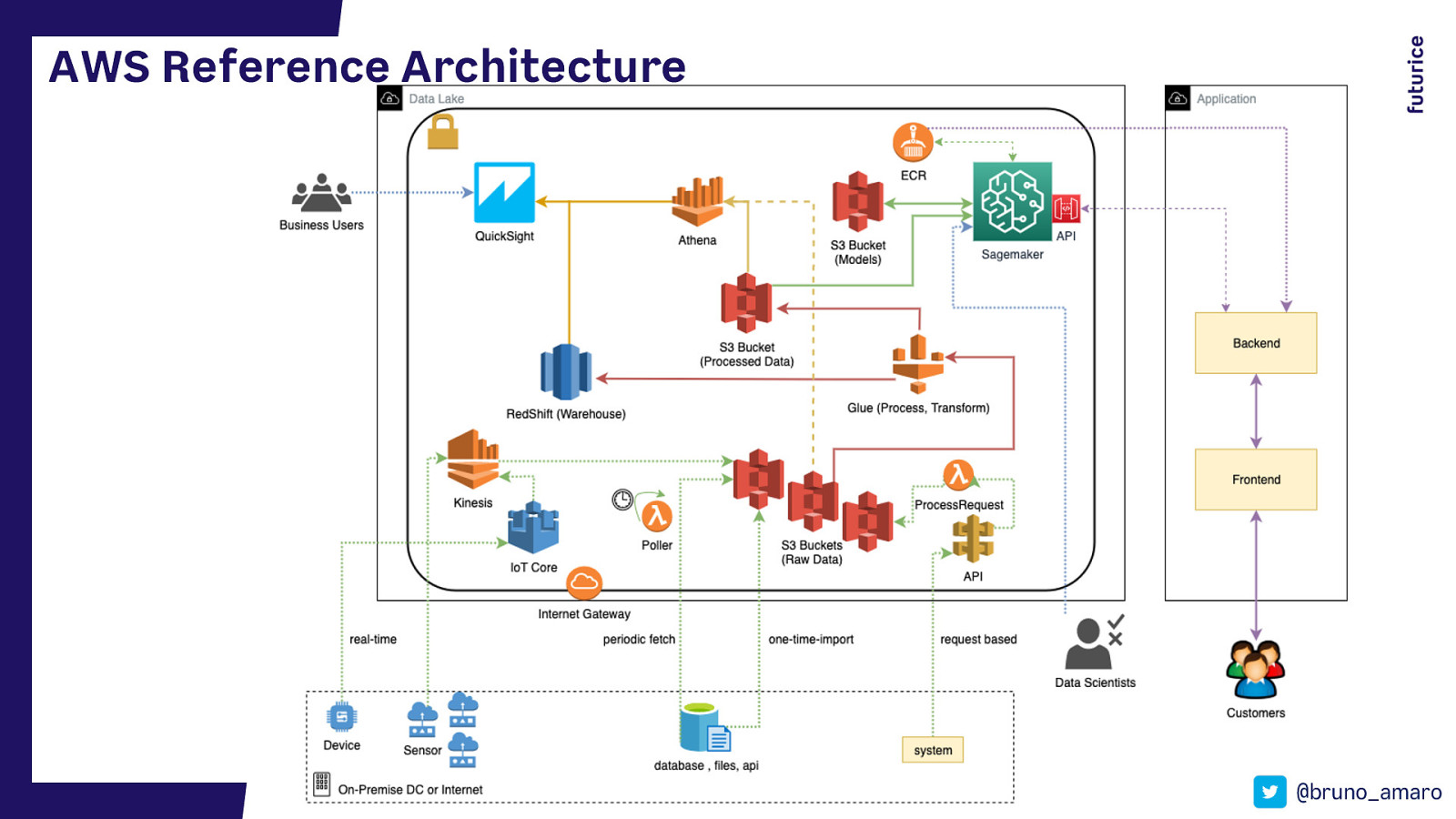
AWS Reference Architecture @bruno_amaro
Slide 28

MNIST WITHOUT LABELS Can we predict what the number on the image is? Clustering/Classification Algorithm K-MEANS AWS GroundTruth would help here! • Unsupervised learning • Gathers a list of attributes and attempts to group (cluster) them based on how similar they are. • MNIST dataset Source: https://researchgate.net, http://yann.lecun.com/exdb/mnist/ Similarity is calculated based on the distance between attributes. • You must define the number of features and clusters Note: in AWS, CPU instances are recommended or 1 GPU @bruno_amaro
Slide 29

// HANDS-ON LAB AWS Sagemaker • Amazon SageMaker automatically configures and optimizes TensorFlow, Apache MXNet, PyTorch, Chainer, Scikit-learn, SparkML, Horovod, Keras, and Gluon. • Commonly used machine learning algorithms are built-in and tuned for scale, speed, and accuracy with over a hundred additional pre-trained models and algorithms available in AWS Marketplace. • You can also bring any other algorithm or framework by building it into a Docker container. Source: AWS How can you deploy models in AWS (Sagemaker)? Offline usage (e.g. ECR/Docker) Online usage (e.g. API) Go to Sagemaker Hands-on Lab (AWSLABS) > https://github.com/brunoamaroalmeida/hitchhiker-cloud-ml-aws/ @bruno_amaro
Slide 30
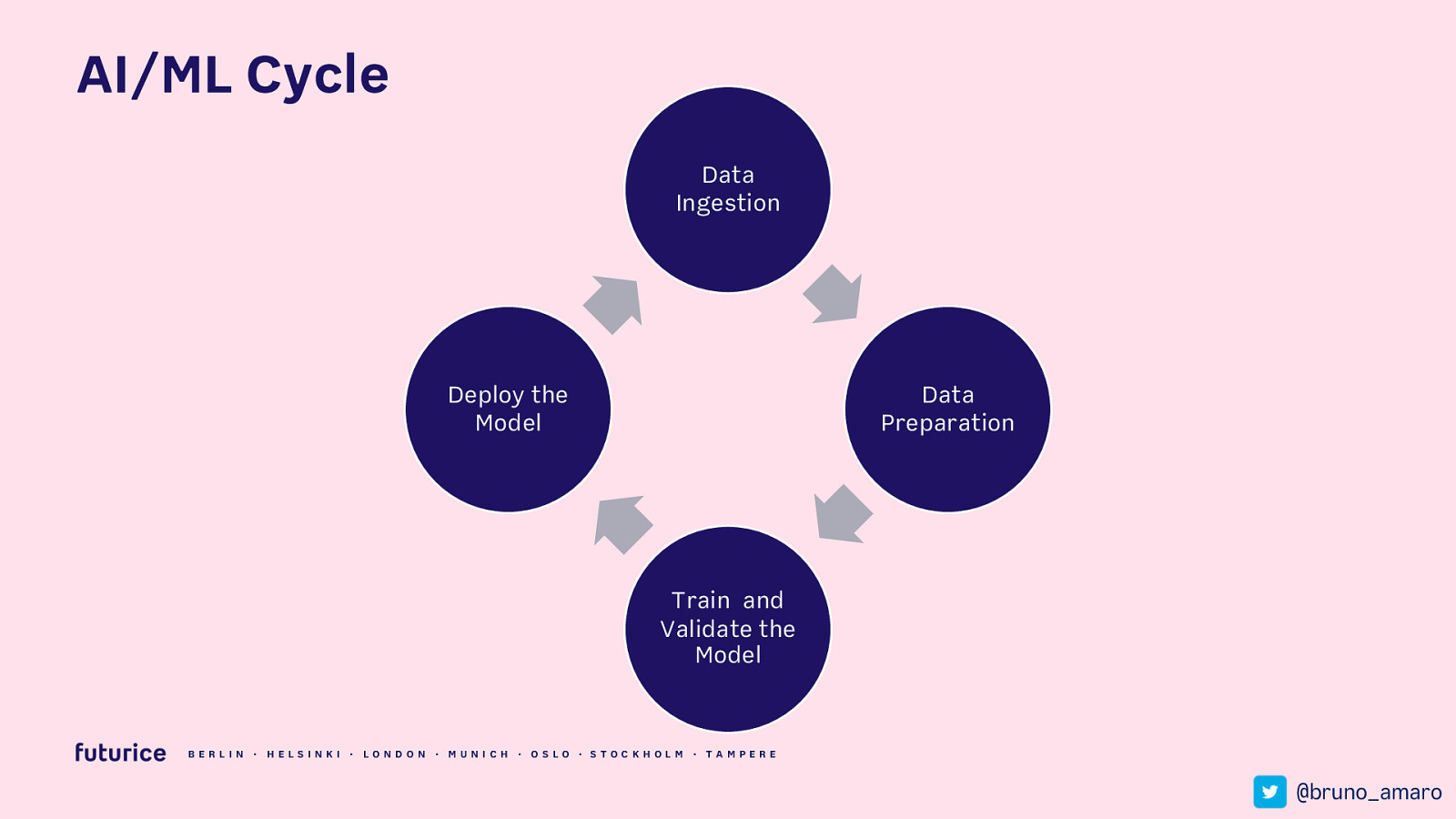
AI/ML Cycle Data Ingestion Deploy the Model Data Preparation Train and Validate the Model BERLIN · HELSIN K I · LON DON · MUN ICH · OSLO · STOCK HOLM · TAMPERE @bruno_amaro
Slide 31
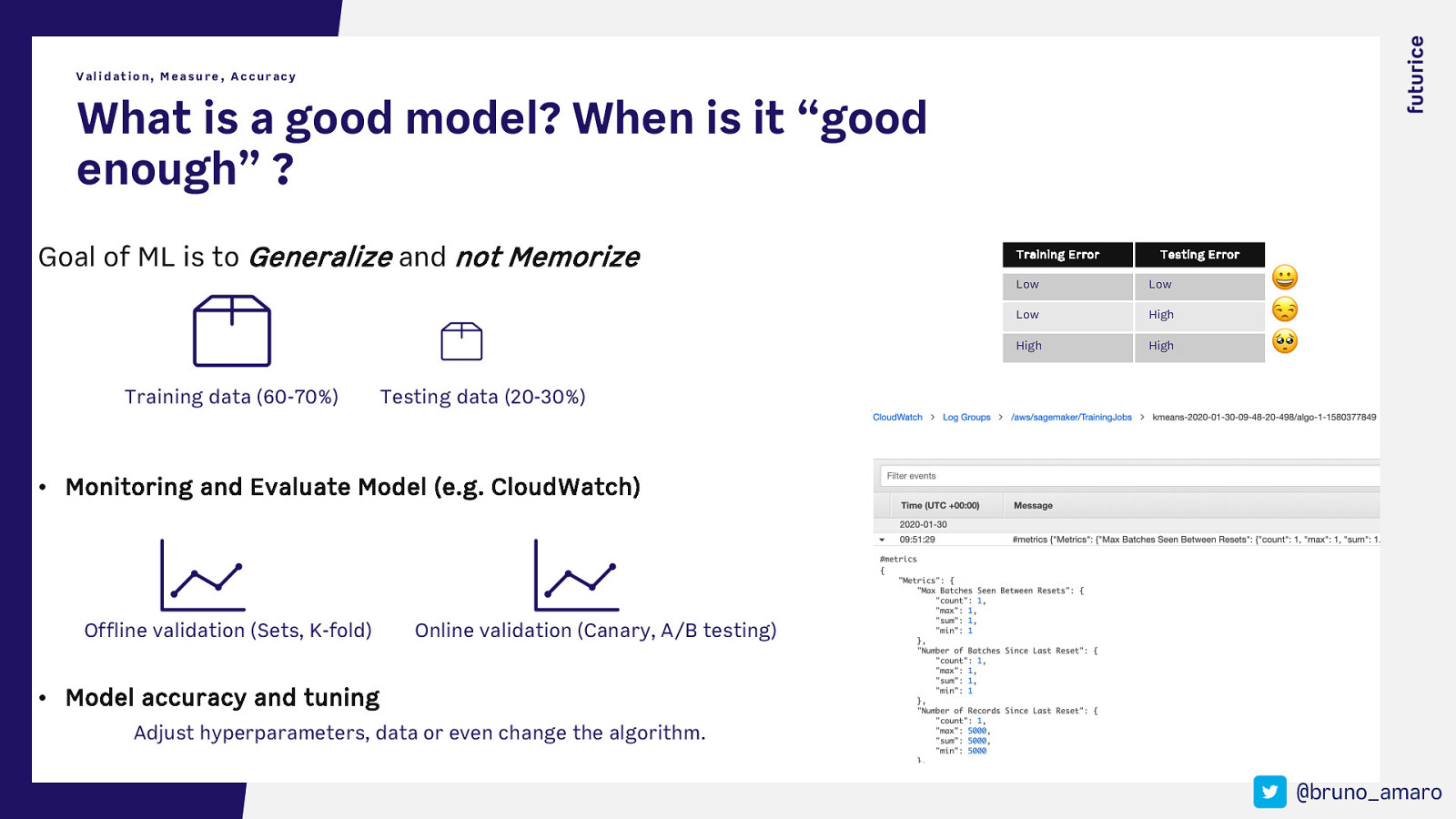
Validation, Measure, Accuracy What is a good model? When is it “good enough” ? Goal of ML is to Generalize and not Memorize Training data (60-70%) Training Error Testing Error Low Low Low High High High 😀 😒 🥺 Testing data (20-30%) • Monitoring and Evaluate Model (e.g. CloudWatch) Offline validation (Sets, K-fold) Online validation (Canary, A/B testing) • Model accuracy and tuning Adjust hyperparameters, data or even change the algorithm. @bruno_amaro
Slide 32

// HANDS-ON AWS Rekognition • Amazon Rekognition makes it easy to add image and video analysis to your applications using proven, highly scalable, deep learning technology that requires no machine learning expertise to use. • With Amazon Rekognition, you can identify objects, people, text, scenes, and activities in images and videos, as well as detect any inappropriate content. • Amazon Rekognition also provides highly accurate facial analysis and facial search capabilities that you can use to detect, analyze, and compare faces for a wide variety of user verification, people counting, and public safety use cases. Source: AWS What kind of metadata can you get? Identifying Labels Celebrity Recognition Moderation Labels, Safe Search Go to Rekognition Hands-on Lab > https://github.com/brunoamaroalmeida/hitchhiker-cloud-ml-aws/ @bruno_amaro
Slide 33

// HANDS-ON AWS Comprehend • Amazon Comprehend is a natural language processing (NLP) service that uses machine learning to find insights and relationships in text. No machine learning experience required. • Amazon Comprehend uses machine learning to help you uncover the insights and relationships in your unstructured data. The service identifies the language of the text; extracts key phrases, places, people, brands, or events; understands how positive or negative the text is; analyzes text using tokenization and parts of speech; and automatically organizes a collection of text files by topic. You can also use AutoML capabilities in Amazon Comprehend to build a custom set of entities or text classification models that are tailored uniquely to your organization’s needs. Source: AWS What kind of metadata can you get? Detect Sentiment Text Categories, Entities Go to Comprehend Hands-on Lab > https://github.com/brunoamaroalmeida/hitchhiker-cloud-ml-aws/ @bruno_amaro
Slide 34

// HANDS-ON AWS Transcribe • Amazon Transcribe makes it easy for developers to add speech-to-text capability to their applications. Audio data is virtually impossible for computers to search and analyze. Therefore, recorded speech needs to be converted to text before it can be used in applications. Historically, customers had to work with transcription providers that required them to sign expensive contracts and were hard to integrate into their technology stacks to accomplish this task. Many of these providers use outdated technology that does not adapt well to different scenarios, like low-fidelity phone audio common in contact centers, which results in poor accuracy. Source: AWS What kind of metadata can you get? Speech to Text Try out Transcribe in the AWS Console @bruno_amaro
Slide 35

- // Next Steps, Feedback and Q&A @bruno_amaro
Slide 36

Next Steps Interesting courses and certifications AWS § https://github.com/awslabs/amazon-sagemakerexamples § AWS Machine Learning Specialty Certification § AWS Data Analytics Specialty Certification Data Science (deep-dive) § Machine Learning Coursera course by Stanford University § Practical Deep Learning for Coders § Machine Learning by Andrew Ng Photo by Ricardo Rocha on Unsplash @bruno_amaro
Slide 37

Thank you! Kiitos! Danke! Tack! Bruno Amaro Almeida P RINC IP AL ARC HITE C T & ADV ISOR Cloud, DevOps, Security, Data Engineering & AI Reach out on: @bruno_amaro @brunoamaroalmeida BERLIN · HELSIN K I · LON DON · MUN ICH · OSLO · STOCK HOLM · TAMPERE