20-Minutes to Kickstart your AWS AI & ML Knowledge Index Data Natives Unlimited 2020 Bruno Amaro Almeida BERLIN · HELSIN K I · LON DON @bruno_amaro · MUN ICH · OSLO · STOCK HOLM · TAMPERE Photo by Christian Englmeier on Unsplash
Slide 1

Slide 2

Hello! Thank you! What can you expect from this session? Kiitos! • Basic Data Science concepts Danke! • AI and Machine Learning landscape in AWS • Data Architecture fundamentals in AWS Tack! • What does it mean to build, train and deploy a ML Bruno Amaro Almeida HE AD OF ARC HITE C TU RE @ FU TU RIC E AWS AP N AMB ASSADOR Cloud, DevOps, Security, Data Engineering & AI model in AWS? Reach out on: @bruno_amaro @brunoamaroalmeida BERLIN · HELSIN K I · LON DON · MUN ICH · OSLO · STOCK HOLM · TAMPERE
Slide 3
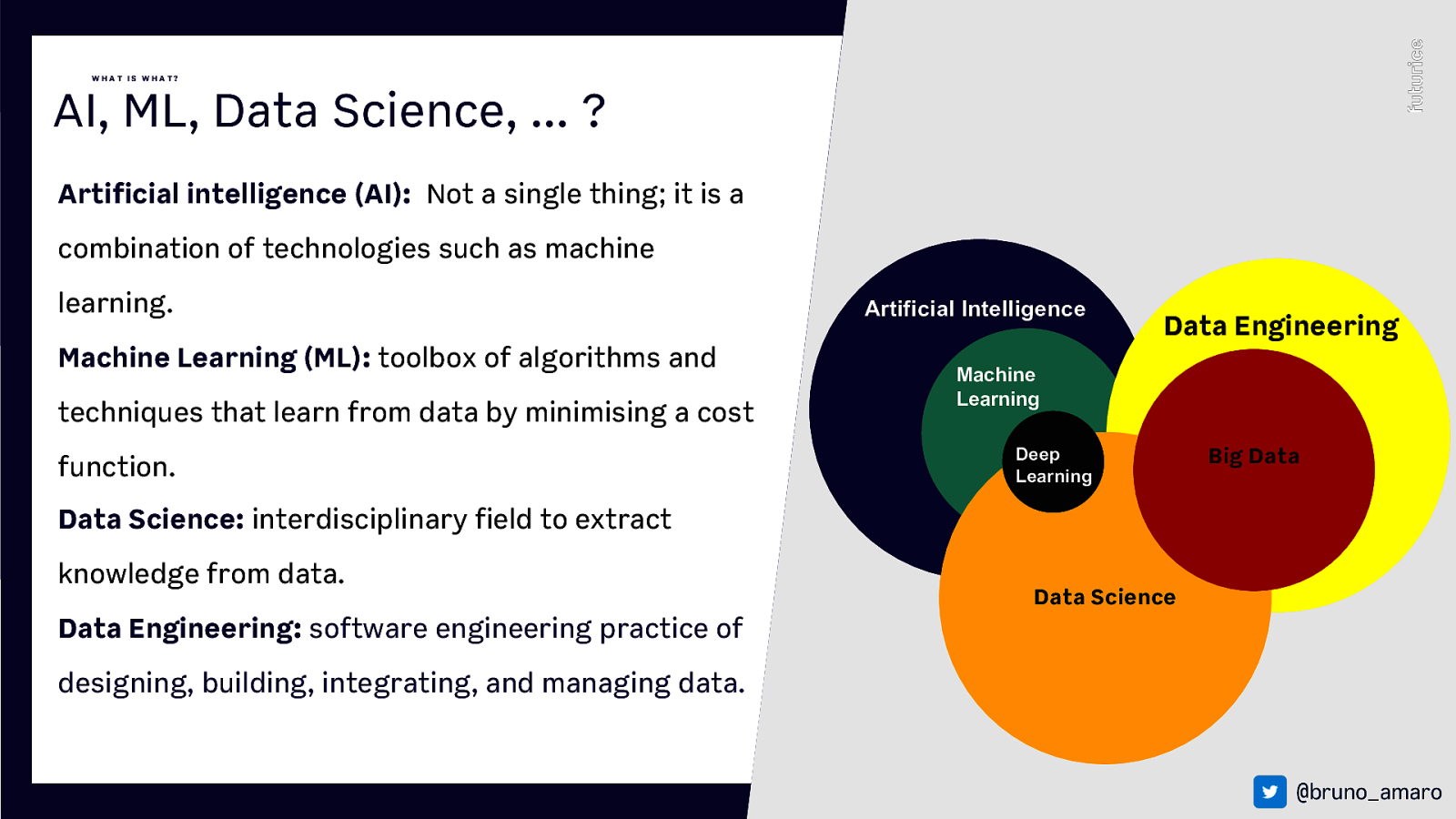
W HAT IS W HAT? AI, ML, Data Science, … ? Artificial intelligence (AI): Not a single thing; it is a combination of technologies such as machine learning. Machine Learning (ML): toolbox of algorithms and techniques that learn from data by minimising a cost function. Artificial Intelligence Data Engineering Machine Learning Deep Learning Big Data Data Science: interdisciplinary field to extract knowledge from data. Data Science Data Engineering: software engineering practice of designing, building, integrating, and managing data. @bruno_amaro
Slide 4
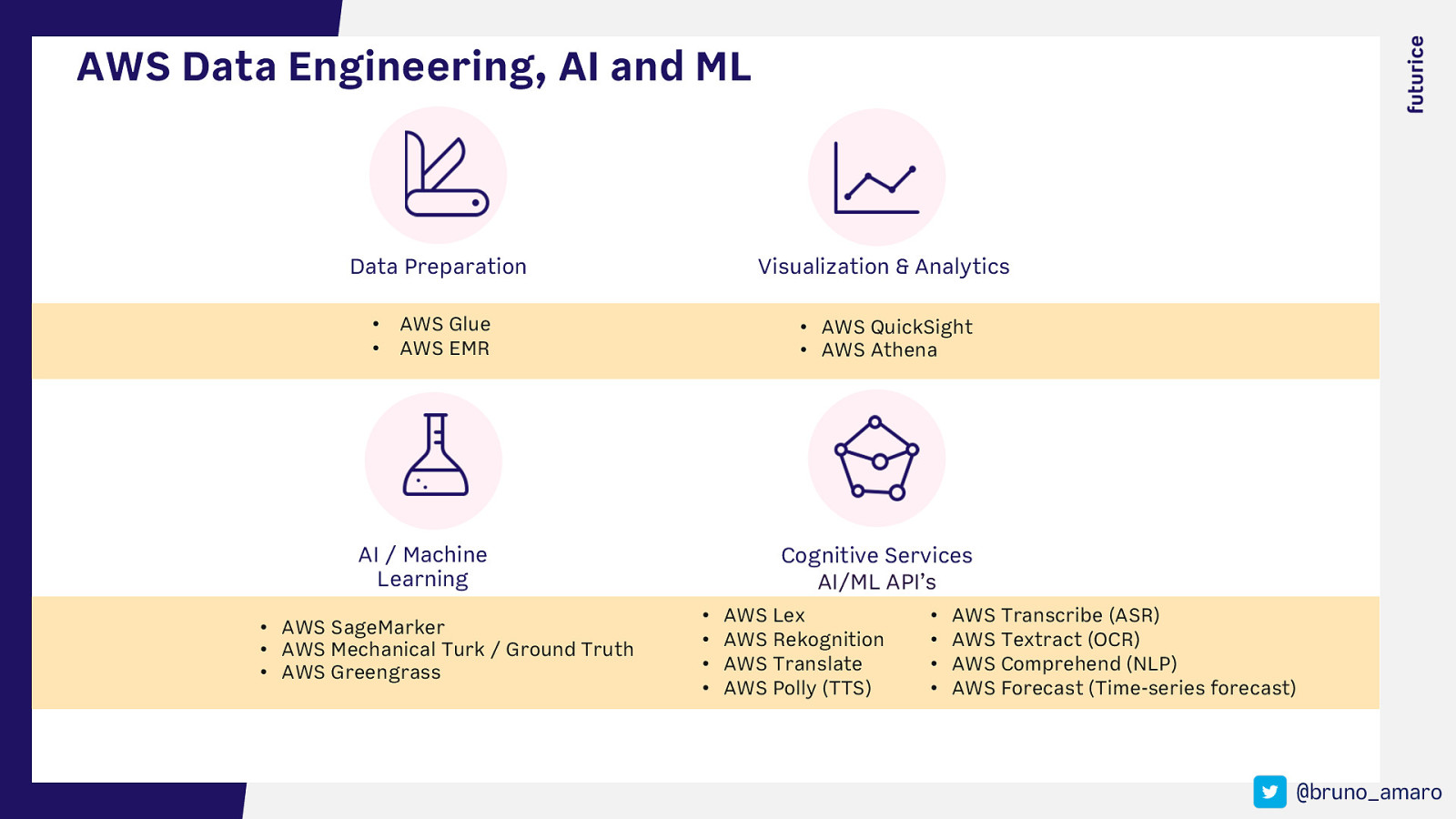
AWS Data Engineering, AI and ML Data Preparation • • Visualization & Analytics AWS Glue AWS EMR • AWS QuickSight • AWS Athena AI / Machine Learning Cognitive Services AI/ML API’s • AWS SageMarker • AWS Mechanical Turk / Ground Truth • AWS Greengrass • • • • AWS Lex AWS Rekognition AWS Translate AWS Polly (TTS) • • • • AWS Transcribe (ASR) AWS Textract (OCR) AWS Comprehend (NLP) AWS Forecast (Time-series forecast) @bruno_amaro
Slide 5
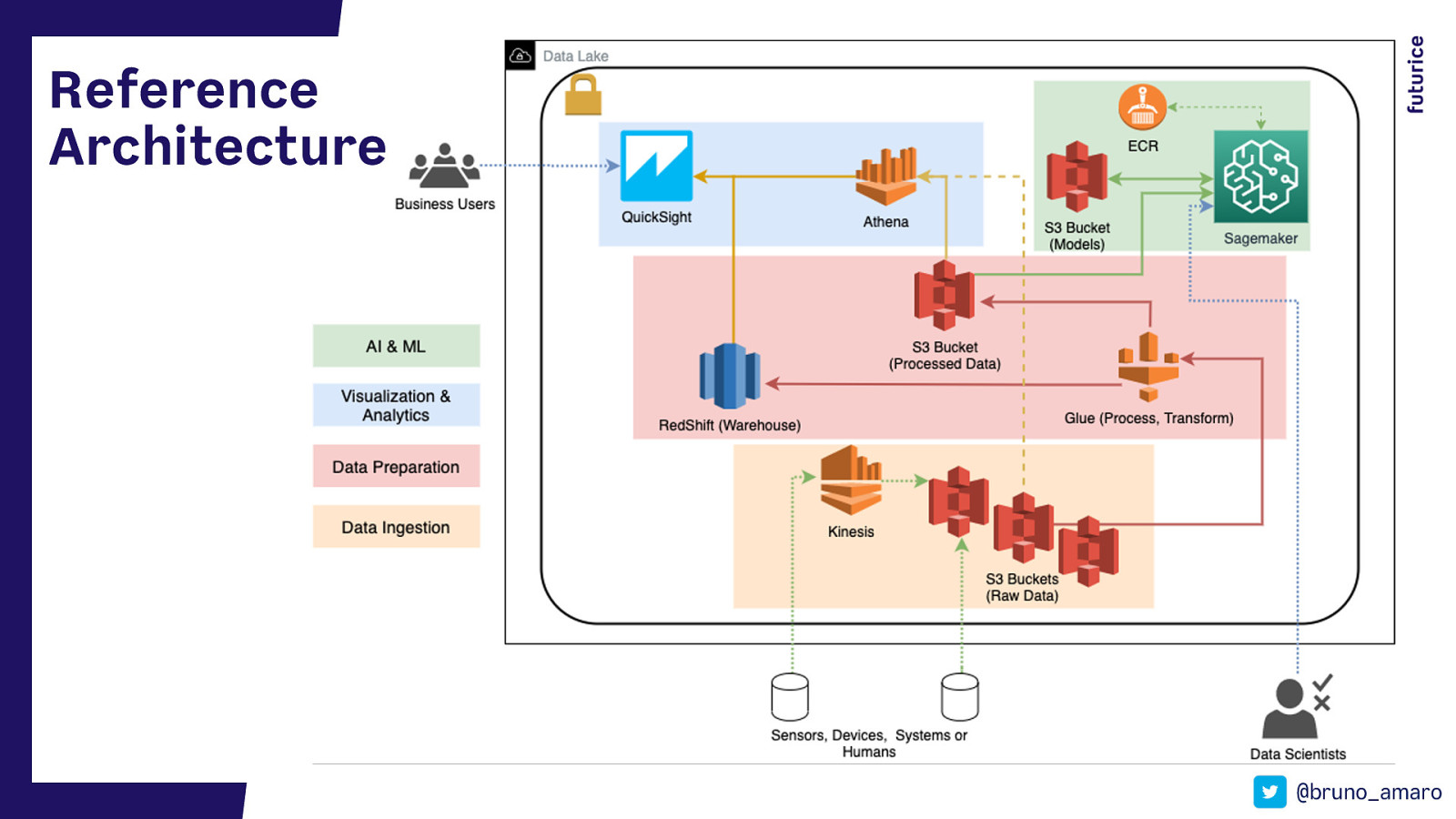
Reference Architecture @bruno_amaro
Slide 6
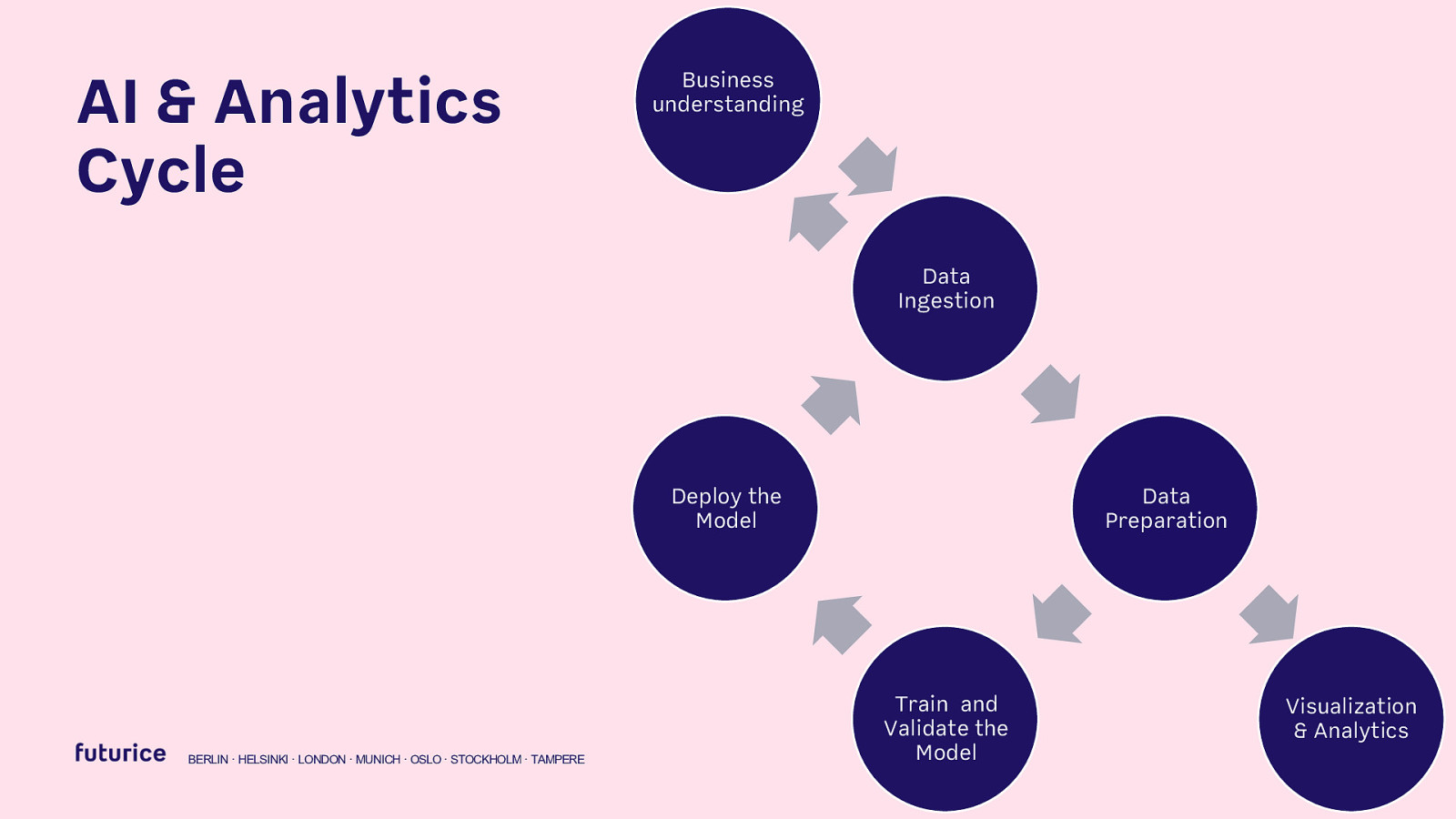
AI & Analytics Cycle Business understanding Data Ingestion Deploy the Model BERLIN · HELSINKI · LONDON · MUNICH · OSLO · STOCKHOLM · TAMPERE Data Preparation Train and Validate the Model Visualization & Analytics
Slide 7

DATA PREPARATION Data Preparation: What, Why, How? A What is data preparation? Transforming our data to make it usable by Machine Learning and / or Analytics B • Over simplification: Algorithms <3 numbers • Algorithms need a lot of data and with good quality to be efficient. How? • Extract: read the data into a usable format (json, csv, parquet, etc) Process: Extract, Transformation, Load (ETL, ELT) • Ways to do Transformation: Categorical Encoding, Feature • Transformation: clean & transform features so that the data can be usable by algorithms or analysis Load: write the new data into a place that can be usable (data warehouse, object storage, etc) Why is this important? Garbage in < Garbage out > C Engineering, … @bruno_amaro
Slide 8

DATA PREPARATION Ways to transform data: Categorical A Categorical Encoding Encoding and Feature Engineering PhoneBrand Brand_Apple Brand_Samsung Apple 1 0 Samsung 0 1 One-hot encoding Text to Numbers: Nominal vs Ordinal B S M L Text Feature N-gram Term Frequency – Inverse Document Frequency (tf-id) Orthogonal Sparse Bigram (OSB) C N-Gram http://recognize-speech.com/language-model/n-gram-model/comparison Numeric Feature 0 1.0 avg Scaling (e.g. Normalization, Standardization) Binning (e.g. Quantile) z-score To deal with outliers! Groups of similar values 0-17 D Missing data? Too many features? Missing data can be dealt in different ways: supervised learning, mean, median, drop values Feature selection: remove useless features! 18-64 65+ Principle Component Analysis (PCA) is an algorithm that reduces the amount of features @bruno_amaro
Slide 9

ALGORITHMS Algorithms & Validation: Building Intelligence on top of our data > Algorithm (consistent) vs Heuristic (rule of thumb, no consistent outcome) > Supervised Learning (training, labels) vs Unsupervised Learning (no training or supervision) How can you use algorithms in AWS? You can use the algorithms built-in Sagemaker B E R L I N · T A M P E R E H E L S I N K I · L O N D O N · M U N I C H · O S L O · You can purchase algorithms from Marketplace S T O C K H O L M · S T U T T G A R T · You can build your own algorithm (& place it in a Docker container) @bruno_amaro
Slide 10
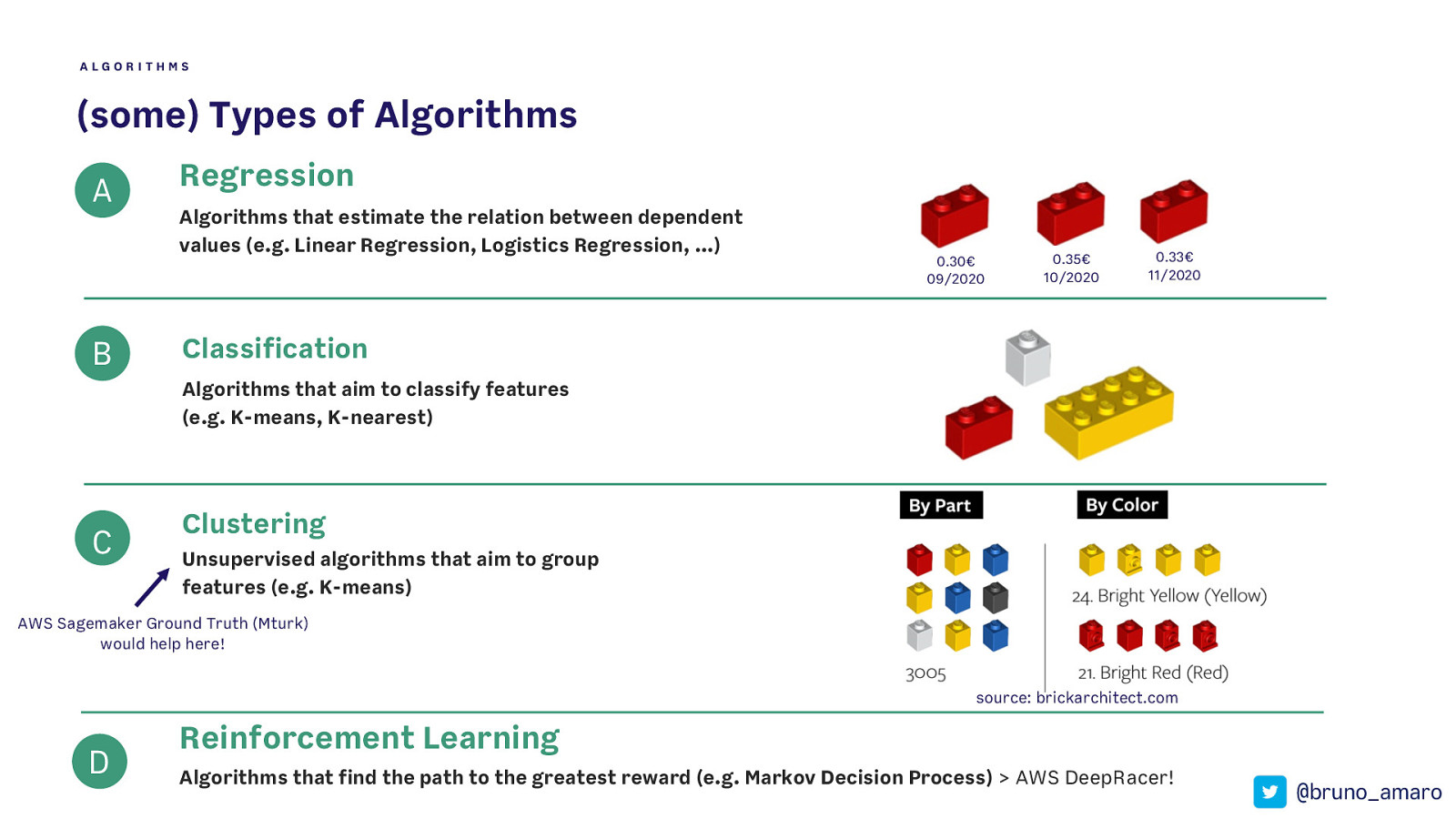
ALGORITHMS (some) Types of Algorithms A B Regression Algorithms that estimate the relation between dependent values (e.g. Linear Regression, Logistics Regression, …) 0.30€ 09/2020 0.35€ 10/2020 0.33€ 11/2020 Classification Algorithms that aim to classify features (e.g. K-means, K-nearest) C Clustering Unsupervised algorithms that aim to group features (e.g. K-means) AWS Sagemaker Ground Truth (Mturk) would help here! source: brickarchitect.com D Reinforcement Learning Algorithms that find the path to the greatest reward (e.g. Markov Decision Process) > AWS DeepRacer! @bruno_amaro
Slide 11
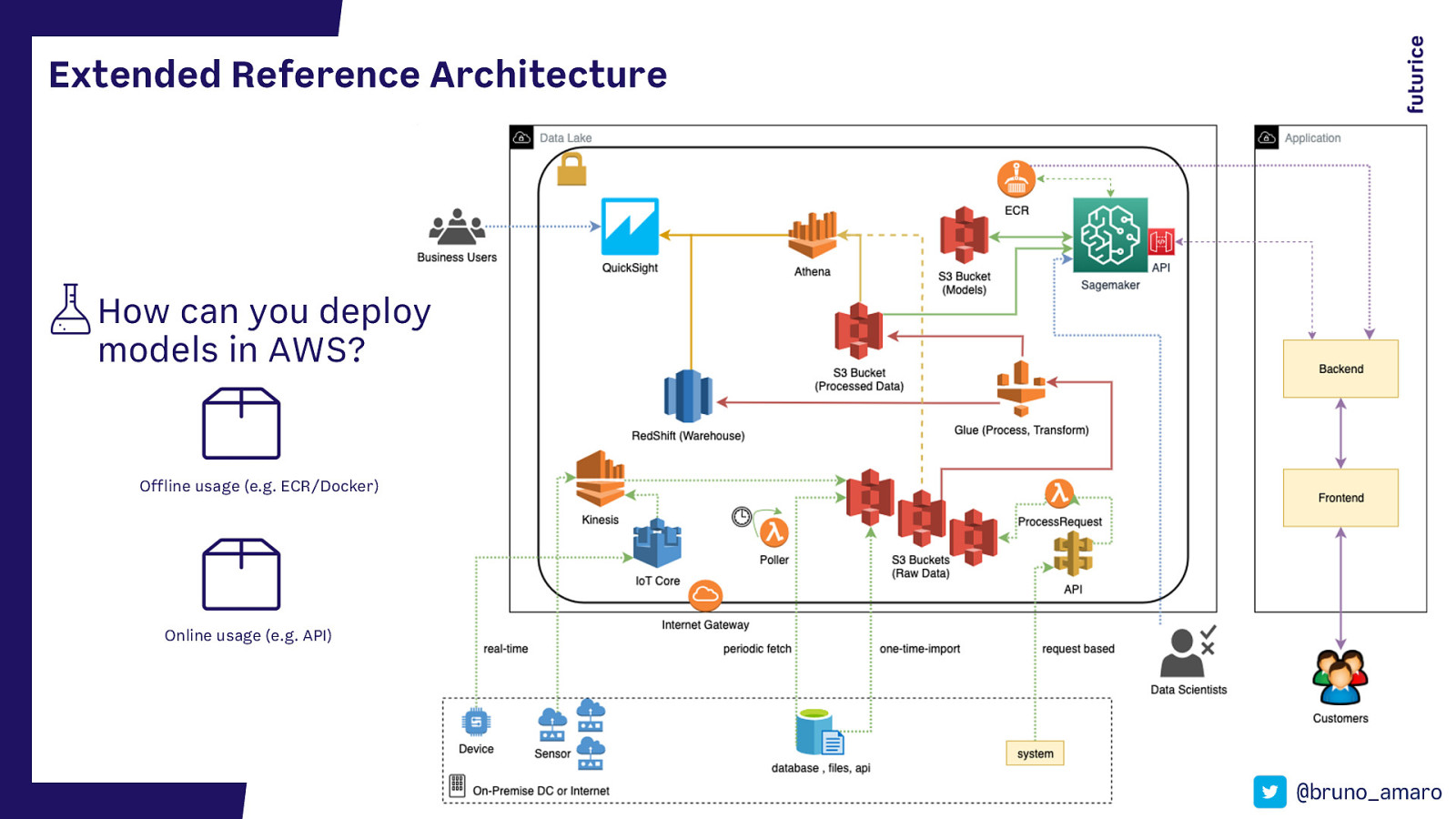
Extended Reference Architecture How can you deploy models in AWS? Offline usage (e.g. ECR/Docker) Online usage (e.g. API) @bruno_amaro
Slide 12
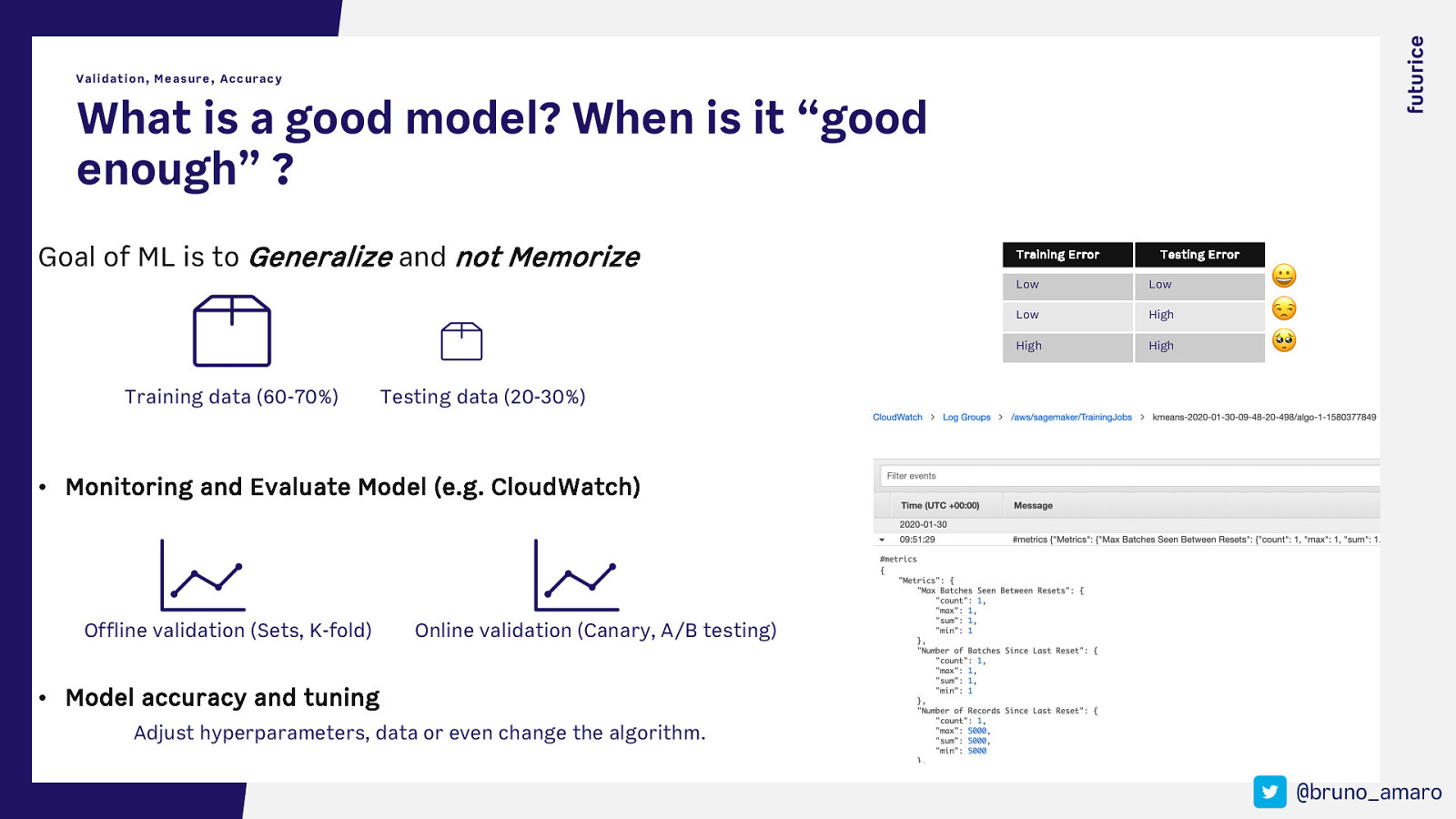
Validation, Measure, Accuracy What is a good model? When is it “good enough” ? Goal of ML is to Generalize and not Memorize Training data (60-70%) Training Error Testing Error Low Low Low High High High 😀 😒 🥺 Testing data (20-30%) • Monitoring and Evaluate Model (e.g. CloudWatch) Offline validation (Sets, K-fold) Online validation (Canary, A/B testing) • Model accuracy and tuning Adjust hyperparameters, data or even change the algorithm. @bruno_amaro
Slide 13

Business understanding Thank you! Kiitos! Danke! Tack! Data Ingestion Data Preparation Deploy the Model Bruno Amaro Almeida HE AD OF ARC HITE C TU RE Train and Validate the Model Cloud, DevOps, Security, Data Engineering & AI Visualization & Analytics Reach out on: @bruno_amaro @brunoamaroalmeida BERLIN · HELSIN K I · LON DON · MUN ICH · OSLO · STOCK HOLM · TAMPERE